
Esta es una guía completa para configurar Screaming Frog y conocer todo lo que te permite esta herramienta.
Si quieres mejorar cualquier aspecto SEO de una web, esta guía será tu amiga.
Empecemos →
Contenidos de la Guía
¿Qué es Screaming Frog y para qué sirve?
Screaming Frog es una herramienta que permite rastrear sitios web de cualquier tamaño.
Siendo capaz de detectar y extraer una gran cantidad de información que tendrás disponible para poder analizar posteriormente.
Se trata de una de las herramientas más utilizadas en el SEO debido a todas las ventajas y opciones que te permite realizar.
¿Cómo funciona Screaming Frog?
La herramienta Screaming rastrea tu sitio igual qué lo haría Google.
De esta forma, podrás ver lo que Googlebot encontrará cuando rastree tu sitio.
Facilitándote encontrar errores de forma rápida, ver oportunidades de mejora y una gran cantidad más de opciones
Screaming te aportará datos tan simples como conocer la longitud de un title en tu web, como información mucho más avanzada, por ejemplo:
Buscar todas las páginas que contengan «x» keyword en su texto.
Panel y configuración
Panel
Para empezar a entender la herramienta haremos un pequeño recorrido por el panel, para ver donde deberás buscar cada dato posteriormente:

En la barra superior, se encuentran todos los menús desplegables desde donde configurar como y qué información se quiere buscar, guardar rastreos, exportar y cargar datos o programar rastreos.

Una vez cargada la información, desde las pestañas de abajo y la columna de la derecha, se puede seleccionar qué información se está buscando.
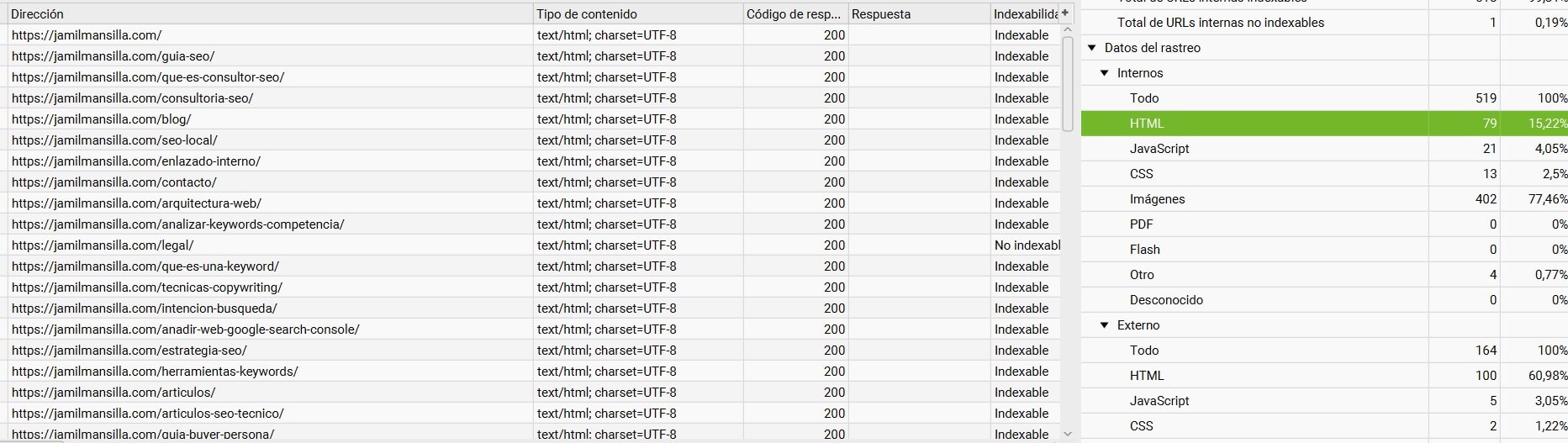
Una vez selecciones la información que deseas ver, en la pantalla central de arriba se mostrarán todas las urls con esa información.
Y si haces clic en una de ellas, en la pantalla inferior te mostrarán datos sobre esa dirección en concreto.

Esta sería una vista muy simple del panel.
Al principio puede parecer una herramienta compleja de entender, pero una vez hayas leído esta guía, comprenderás esta herramienta por completo.
Modos rastreo
En Screaming encontrarás diferentes modos de crawleo.
Modo Spider
El modo spider es el más utilizado, analiza como una araña de Google desde la url que le indiques.
Este es el modo en el que se basará esta guía y el que más utilizarás en tus tareas como SEO.
Modo SERPs
El modo SERPs simplemente te permite cargar metadatos, para comprobar si son óptimos y comprobar como se visualizarán en Google.

Modo lista
Este modo te permite conocer información sobre un listado de urls en concreto.
Para importar las direcciones puedes subir un archivo, copiar y pegar, incluir la dirección de un sitemap o escribirlas manualmente.
¿Para qué puede ser útil el modo lista?
Utilizar esta sección de la herramienta, es una forma rápida de obtener datos cuando sabes donde y qué estás buscando de forma concreta, algunos ejemplos:
- Comprobar que todas las urls del sitemap devuelven un código 200.
- Después de aplicar cambios en algunas páginas, comprobar que se han implementado con éxito.
- Analizar a la competencia, subiendo el listado de tus competidores y comparando ciertos datos, como su page rank con la API de Ahrefs.
Importante
Algo importante que debes saber al utilizar esta función de la herramienta:
- Es necesario configurar el spider, ya que al seleccionar este modo, la configuración por defecto te limita el rastreo a un nivel de profundidad 0.
- Si subes las direcciones de páginas duplicadas no pasa nada, screaming eliminará los duplicados.
- Todas las urls deben comenzar por http o https, por ejemplo ‘www.dirección.com’, no la reconocería.
Modo comparar
La función de comparar rastreos es una joya para monitorizar como evolucionan el SEO de un sitio web.
Podrás conocer qué datos han cambiado entre diferentes rastreos.
Configuración
Un error muy común al empezar a utilizar esta herramienta al principio es no configurar el rastreo.
Si no se configuran los datos antes de realizar la búsqueda, puede que dejes datos sin rastrear o rastrees más de los que se necesitan.
¿Cómo configurar Screaming Frog?
Spider
La configuración de Spider, es el principal lugar desde donde configurar qué datos rastrear y cuáles dejar fuera.
Hagamos un recorrido por este panel:
Rastreo
En la primera pestaña, rastreo, se encuentran diferentes datos para incluir o excluir.
Deberás echarle un ojo antes de tu rastreo y ver cuales te interesa que se encuentren seleccionados.
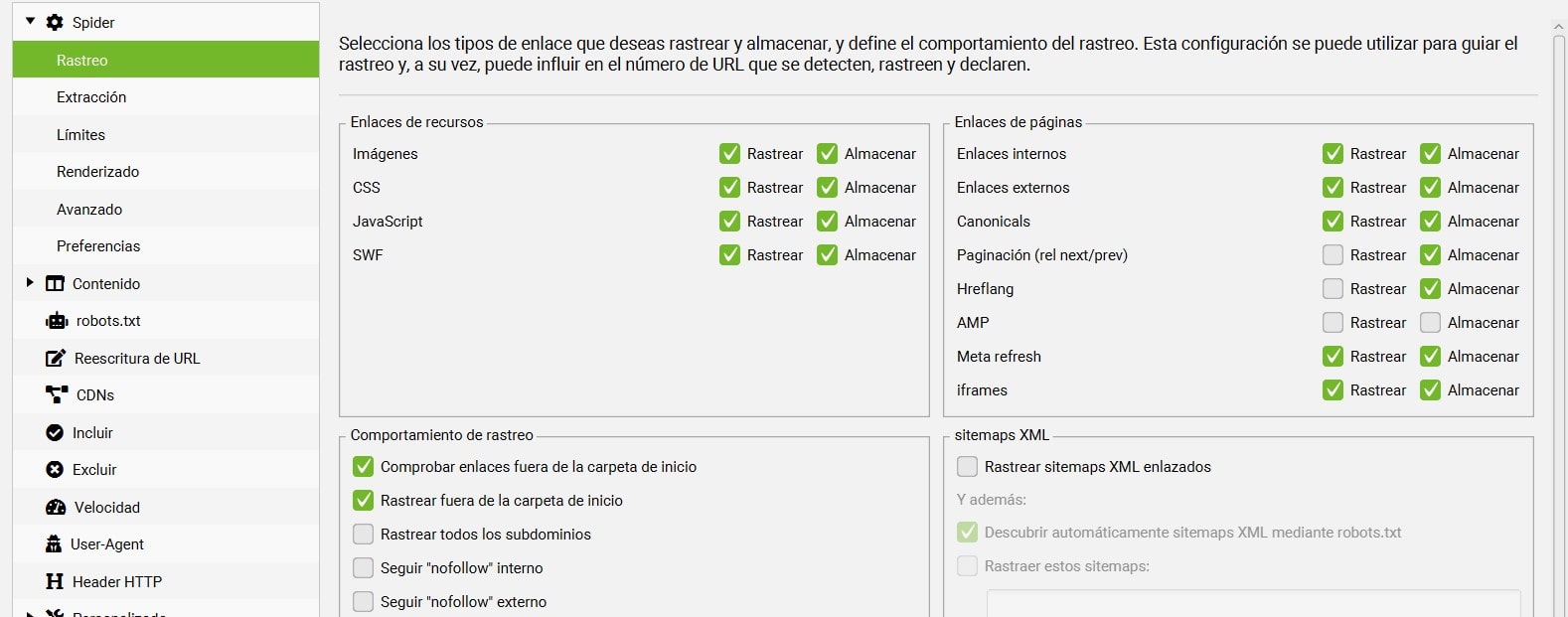
La mayoría de datos serán bastante intuitivos de reconocer si te van a ser útiles o no.
Al marcar la casilla de «rastreo», spider rastreará las direcciones para verificar su código de respuesta y al marcar la casilla de «almacenar», almacenará y mostrará los datos de esas urls.

Por ejemplo, si solo quieres saber qué código de estado devuelven algunas páginas, bastará con rastrear.
Si además, quieres conocer, en caso de que el código de respuesta sea un 301, ver donde se encuentra ese enlace interno.
Deberá estar seleccionada también la casilla de «almacenar».
Algunas anotaciones sobre este apartado:
- Si desmarcas la casilla de imágenes, se excluirán los elementos (img src) pero las imágenes vinculadas se seguirán rastreando. Si deseas excluir las imágenes vinculadas, deberás realizarlo de otra forma, como por ejemplo, utilizando el apartado «excluir» que veremos más adelante.
- Rastrear todos los subdominios. Al marcar esta casilla, screaming, cuando encuentre un subdominio a través de un enlace interno, seguirá rastreando y lo tomará como parte del sitio, de lo contrario, simplemente tomará este como un enlace externo.
- Sitemaps XML. Si marcas la casilla de rastrear sitemaps, tendrás la opción de que el mapa sea descubierto a través del robots.txt si lo tienes implementado. También puedes añadir en el recuadro de abajo el sitemap que desees rastrear.

Extracción
En esta segunda pestaña, se encuentran datos que puedes descartar o incluir para que se almacenen y muestren en relación a las urls y archivos que anteriormente has decidido rastrear.

Algunas anotaciones sobre el apartado de extracción:
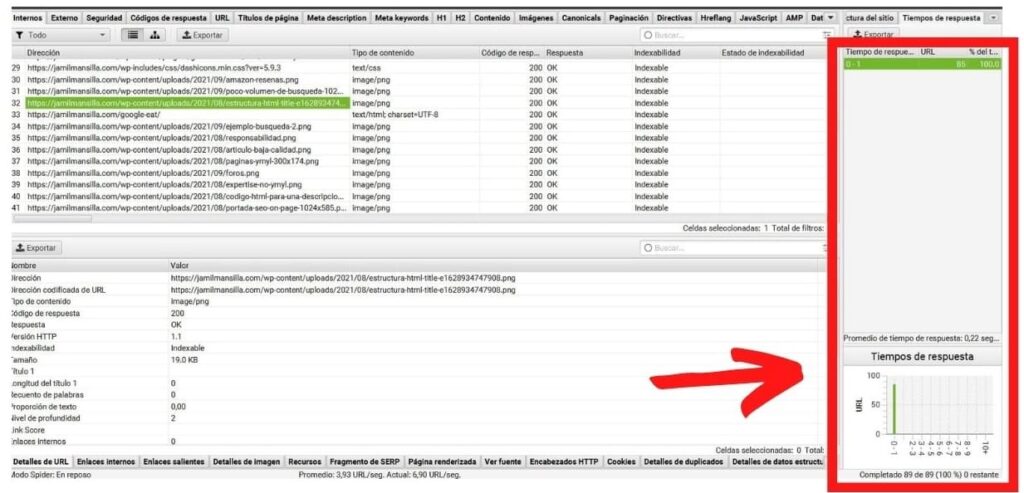
- En detalles de URL → tiempo de respuesta: indica el tiempo en segundos que el spider ha tardado en rastrear esa dirección.
Puede ser una información interesante para conocer como de rápido están respondiendo tus páginas.
Algo que te mostrará de forma gráfica, en la columna de la derecha:
Límites
En la pestaña de límites podrás restringir la cantidad de urls que se rastrean mediante las diferentes opciones que ofrece spider para limitar la cantidad de direcciones a rastrear.

Ejemplo de limitación de rastreos: ¿Cómo limitar rastreos por directorios?
Limitar un rastreo por directorios hará que se reduzca el rastreo a las urls que se encuentran a partir de esa subcarpeta.
Para limitar el rastreo por directorios, simplemente incluye la dirección URL por la que quieres comenzar el rastreo en la barra superior.

Por ejemplo, si incluyo la url https://jamilmansilla.com/blog/, solo se rastrearán las urls que se encuentren a partir de /blog/.
Y desmarca la casilla “Rastrear fuera de la carpeta de inicio”, que se encuentra en Configuración > Spider > Rastreo.
De lo contrario, también rastreará los enlaces internos que se vinculan desde este subdirectorio, aunque no se encuentren dentro de él.
Renderizado
En este apartado seleccionas la opción del renderizado del código.
Si dejas configurada la opción que viene por defecto, solo texto, se renderizará el código HTML puro.

Si configuras la opción javaScript ejecutará este código y te mostrará una captura de como se está visualizando.

Esta opción, lógicamente, será la que más recursos le cueste a screaming, por lo que llevará más tiempo el rastreo.
Avanzado
La pestaña avanzado, ofrece más opciones de configuración para tratar la información que vas a recopilar en el rastreo.
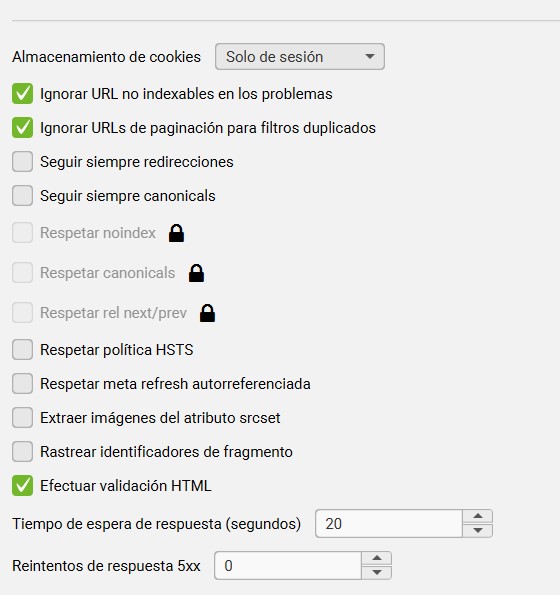
Pasamos a comentar los puntos más importantes de este apartado que debes conocer:
- La opción seguir siempre redirecciones, seguirá un código 3xx hasta su url final, independientemente de que hayas limitado la profundidad de rastreo.
Esto es especialmente útil si has hecho una migración, ya que se pueden crear cadenas de redireccionamientos.
- Al marcar seguir siempre canonicals, ejecutará que en el modo lista siga los canonicals hasta la URL de destino de redireccionamiento final, ignorando el límite de profundidad de rastreo también.
Esto sucede, cuando se crean cadenas de canonicals, donde una url, que tiene un canonical que a su vez tiene otro canonical.
- Seleccionar «respetar noindex, canonicals y rel next/prev» servirán para limitar la información que se muestre en screaming. En este caso, se seguirán rastreando los enlaces que se encuentren en su contenido, pero no te mostrarán estas urls.
- Al marcar «respetar noindex» no aparecerán las urls con la etiqueta noindex.
- «Respetar canonicals», no mostrará las urls con un canonical que no apunte a sí mismas.
- Y al marcar la casilla: «respetar rel next prev», solo mostrará la primera url de la secuencia de paginaciones.
- La opción «extraer imágenes del atributo srcset», en el caso de que se cuente con imágenes con este atributo, algo poco común, pero de ser así, al marcar esta casilla, screaming te las mostrará.
- «Rastrear identificadores de fragmento» hace que una dirección con fragmentos hash, es decir, urls que ves de esta forma: https://jamilmansilla.com/vocabulario-seo/#seo, se traten como páginas independientes.
- La casilla, «tiempo de respuesta», configura el tiempo máximo que el spider dedicará a rastrear cada dirección, de no conseguirse en este tiempo, devolverá un código de respuesta 0.
- Y «reintentos de respuesta 5xx», como el nombre indica, será el nº de veces que screaming intenta rastrear una dirección a la que el servidor no está respondiendo.
Preferencias
La última pestaña de configuración de spider, viene más relacionada con los aspectos básicos del SEO On Page.
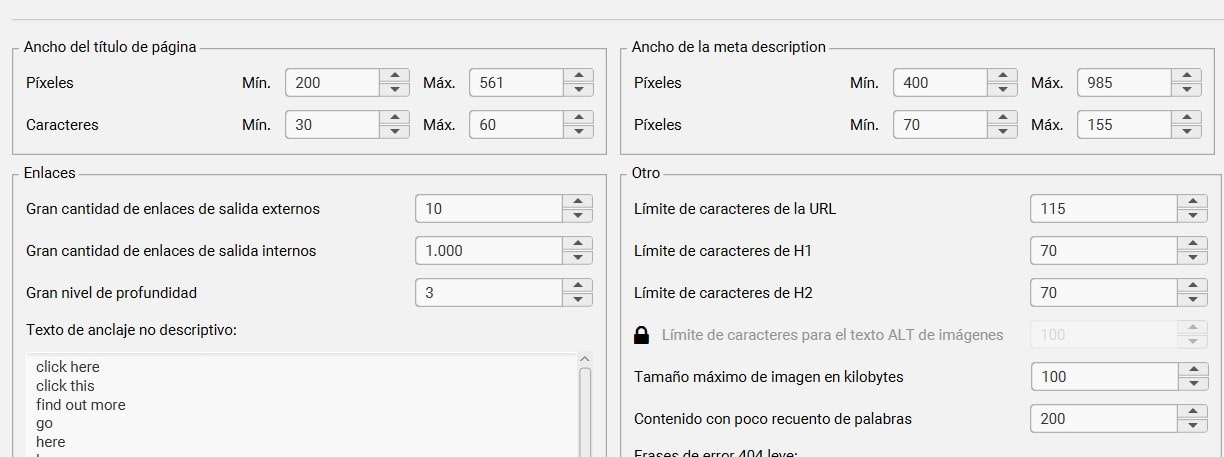
En este apartado, modificarás las preferencias que vienen por defecto respecto a temas relacionados con el contenido y enlaces.
Robots.txt
Configurar robots.txt
En la configuración de robots, tienes varias opciones:

- Respetar el robots.txt. En este caso, al igual que si se tratase de un bot de Google, screaming no crawlea las urls bloqueadas.
- Ignorar el robots.txt. Con esta configuración, omite la información del robots y crawlea todos los enlaces que se encuentre.
- Ignorar el robots.txt pero informar de su estado. Esta opción significa que accederá a rastrear todas las urls, estén bloqueadas o no, pero te indicará si se encuentran bloqueadas en el archivo.
Robots.txt personalizado
En este apartado, la herramienta te permite añadir el archivo robots de tu sitio y modificarlo.

Esta opción será útil para poder hacer pruebas sin necesidad de tener que modificar el archivo original.
Incluir y excluir
Los apartados de configuración «Incluir y Excluir» son una de las configuraciones más útiles de la herramienta screaming.
Sobre todo, cuando rastrees sitios grandes, con esta opción podrás restringir el crawleo solo a la parte del sitio que te interesa.
Por ejemplo, en una web multi idioma, puede que te interese rastrear solo las urls que hagan referencia al inglés.

En los apartados incluir y excluir, podrás segmentar tu rastreo, incluyendo que solo se rastree una parte del sitio o excluyendo parte del sitio o combinando ambas.
Lo que debes saber es que al excluir una url, el spider no la rastrea, por lo tanto, tampoco rastreará los enlaces internos que contenga, aunque estos no estén excluidos.
Por ello, rastrear un sitio entero y filtrar por la sección deseada, puede que recoja más datos que empezar con esta limitación.
¿Cómo limitar el rastreo con la función Incluir y excluir de Screaming Frog?
Limitar rastreo con la función incluir
La función incluir, que se encuentra dentro del apartado de configuración, se puede utilizar para limitar el rastreo a través del uso de expresiones regulares.
En este caso, vamos a explicar como limitar el rastreo, cuando quieras seleccionar las urls que contienen un cierto término en su dirección url.
Por ejemplo, supongamos que quieres extraer todas las urls que contienen “seo” y “screaming” en la url.
Para hacer esto, acude a la sección de “Incluir” y añade las consultas: “seo|screaming”.
Y la segunda acción a realizar es incluir la dirección web a rastrear.
Es importante, que el rastreo se inicie desde una url donde se encuentran vinculadas las páginas que desees rastreas.
En mi caso, seleccioné el blog.
Y el resultado será que screaming nos devuelve todas las páginas que contienen estas consultas en su dirección url.

Esto es algo muy útil para tratar con tiendas ecommerce y filtrar por x tipo de producto.
Limitar rastreo con la función excluir
La función excluir de screaming frog permitirá excluir aquellas partes del sitio que son irrelevantes.
Puedes hacer uso de esta función, configurándose de la misma forma que la función incluir, pero con el objetivo de excluir aquellas partes del sitio que no te interesan.
Velocidad
El apartado de configuración de velocidad sirve para ajustar la rapidez con la que screaming rastrea el sitio, donde:
- Max. Hilos/s: es el número de arañas que rastrean por segundo.
- Max. URLS: es el número de urls que se rastrean por segundo.
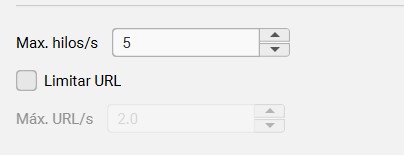
¿Cuándo es conveniente modificar esto? La respuesta es cuando recibimos señales de que el servidor se está sobrecargando (por ejemplo muchos errores 500 o 403).
En este caso, puedes limitar el número de urls que se rastrean por segundo.
User – Agent
Esta función permite elegir el agente de usuario que rastreará el sitio web.
Screaming, cuenta con su propio user – agent y es el que viene establecido por defecto, pero permite más opciones.

Enlaces personalizados
Screaming te muestra la posición donde se encuentra un elemento (menú, footer, sidebar…) Esto es muy útil para identificar un enlace más fácilmente.
O para analizar el enlazado interno, ya que te interesa saber si una página tiene muchos enlaces internos porque se encuentra en el menú o si son enlaces con texto ancla.
Esto lo puedes ver en Configuración > Personalizado > Posición de enlaces.

Para identificar cada sección, screaming interpreta los elementos HTML5 del sitio.
Pero cada web está construida de forma diferente y puede que Spider no llegué a reconocerlos de forma adecuada o que te convenga personalizar la ubicación de los enlaces.
Vamos con un ejemplo:
Esta web, cuenta con un sidebar lateral para todas las páginas de servicios, y los enlaces que se encuentran en ellas, por defecto, se muestran dentro del contenido.
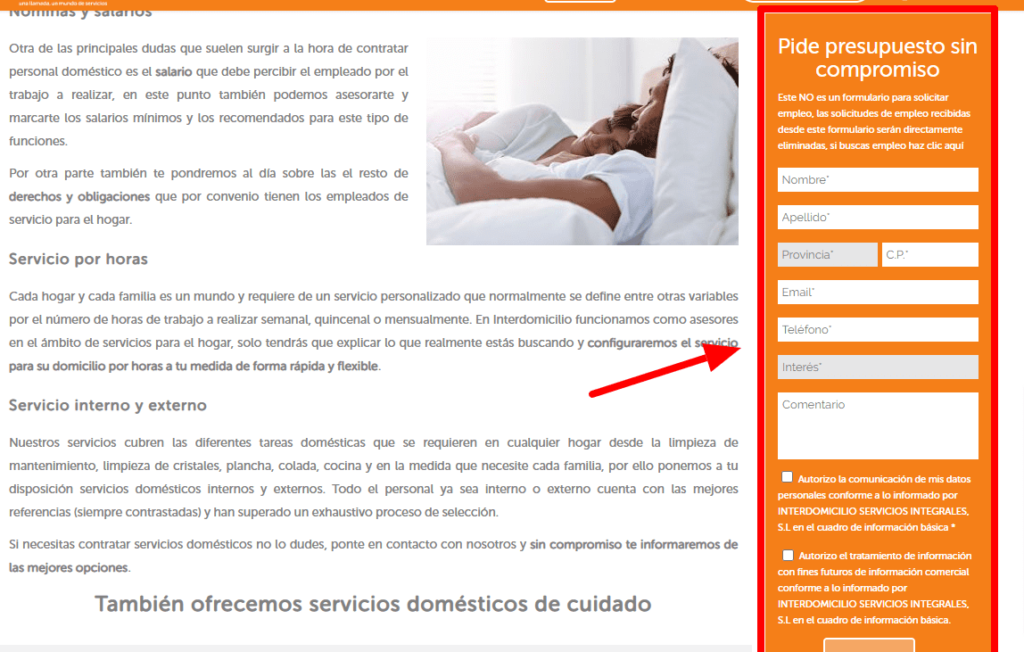
En este caso, para tener un mejor control del enlazado interno, deseamos ubicarlos, ya que es algo repetitivo para todas estas páginas.

En la ruta del enlace que nos está dando screaming, copiamos el id ‘text-60’, que identifica todos los enlaces que parten de este sidebar.
O también puedes copiar otra parte de la ruta del enlace que haga referencia a todos los enlaces que se relacionan con ese elemento.
Vamos al apartado de configuración de posición de enlaces y añadimos una nueva línea.

Es importante saber que la clasificación de estos enlaces sigue un orden de procedencia y dado que «contenido» tiene establecido ‘/’, coincide con cualquier ruta de enlace.
Por lo que debe dejarse siempre en la parte inferior.
Al volver a realizar la búsqueda, ya encontramos que los enlaces se marcan en la ubicación que hemos configurado.

Al igual que es interesante configurar la posición de enlaces, puede que en otros casos, no te interese saber esta información.
Ante un rastreo muy grande, puedes desactivar esta información desde la casilla superior del panel, de esta forma se ahorra memoria y ayudará en acelerar el rastreo.
Almacenamiento
En Archivo → Configuración → Modo de Almacenamiento puedes modificar el tipo de almacenamiento que screaming está empleando.

Screaming frog tiene dos opciones de almacenamiento:
- De memoria. Este modo utiliza la memoria RAM para almacenar y procesar datos, es la que viene por defecto y la que más rápido rastrea.
- En base de datos. En este caso, la información y rastreos pasan a almacenarse en la base de datos. Utilizar esta configuración principalmente será conveniente para rastrear sitios muy grandes, a partir de 500k urls.
Utilizar el almacenamiento en base de datos, aunque no estés rastreando sitios muy grandes, puede ser necesario si deseas hacer uso de las funciones de comparación de rastreo y detección de cambios.
Ya que solo están disponibles en este modo.
Y ofrece la ventaja de poder recuperar rastreos, si lo detienes, cierras o borras sin querer.
Sí deseas utilizar este modo, será conveniente utilizar una memoria SSD para evitar sobrecargar la de tu ordenador.
Principales usos de Screaming Frog para SEO
Esta herramienta de crawling, principalmente es utilizada en una asesoría SEO cuando se lleva a cabo una auditoría del sitio web para analizar diferentes aspectos técnicos.
Principales aplicaciones de uso de Screaming Frog:
Códigos de estado HTTP

Encuentra páginas con el protocolo no seguro HTTP.
Estas pueden ser URLs que existen en tu sitio con esta dirección o enlaces internos que se han marcado de esta forma.
URLs amigables

En el apartado de URLs de Screaming encontrarás las direcciones que se pueden considerar no amigables.
La herramienta te agrupará según el error que contiene cada URL.
Títulos
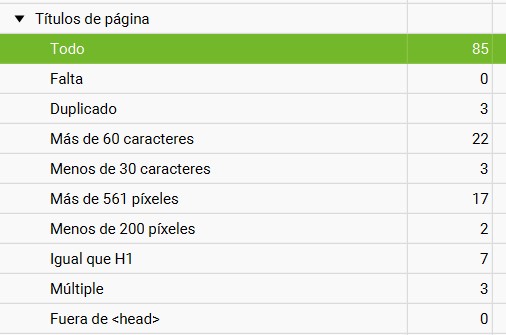
Screaming rastrea el title de cada una de tus páginas y te muestra de forma agrupada los títulos que no son óptimos en tu sitio.
- Páginas sin título.
- Títulos duplicados.
- Demasiado cortos.
- Etc.
Descripciones
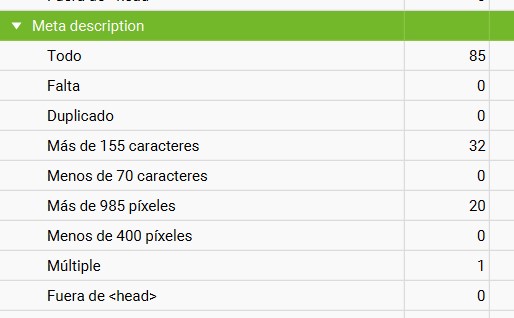
Encuentra las meta description que no se ajustan a las características óptimas para el posicionamiento de tus páginas.
La herramienta te mostrará páginas sin descripción, descripciones múltiples, demasiado largas, etc.
Encabezados
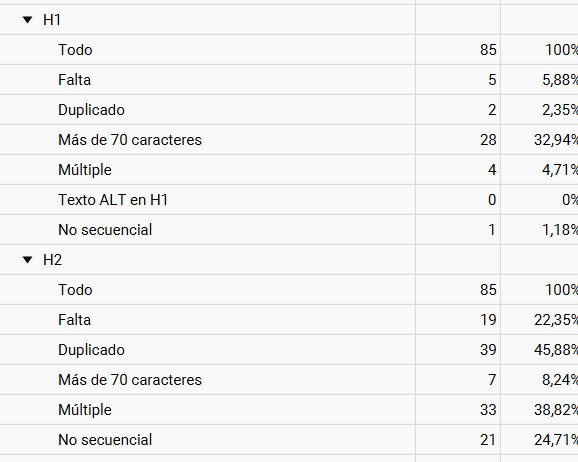
Detecta errores y puntos de mejora en los encabezados H1 y H2 de tu sitio.
Screaming te aporta información muy completa para estos dos headings principales como H2 duplicados, páginas sin H1 o H1 no secuencial, es decir, cuando no es el primer encabezado de la página.
Imágenes

Analiza las imágenes de tu sitio con la herramienta y detecta errores como las imágenes más pesadas en tu web.
O imágenes sin la etiqueta ALT.
Enlazado interno

Puedes analizar y mejorar el enlazado interno con Screaming de una forma muy completa.
Detectando el nivel de profundidad de cada página, link score, número de enlaces recibidos, etc.
Códigos de respuesta 404

Encuentra enlaces internos o externos que generen un código de respuesta 404.
Al seleccionar el enlace roto, Spider te mostrará la dirección donde se encuentra desde la pestaña “enlaces internos».
Redirecciones

Localiza las redirecciones que existen en tu página con Screaming Frog.
La herramienta te mostrará la página con redirección, si se trata de un enlace 301 o diferente, donde se encuentra y donde finaliza.
Robots.txt
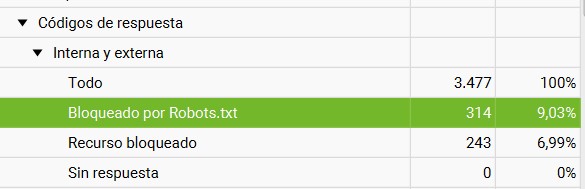
Detecta las páginas bloqueadas por el archivo Robots.txt en tu web.
Comprueba que no se esté denegando acceso a ninguna URL importante y qué sí se estén bloqueando las rutas deseadas.
Sitemap
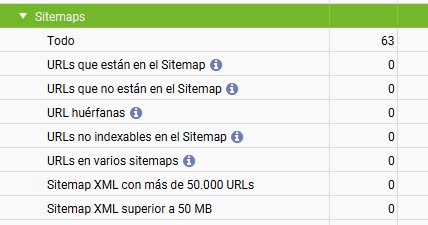
Analiza y encuentra errores en el sitemap.xml de tu sitio web.
Si has configurado previamente el mapa del sitio en el rastreo, en el panel derecho encontrarás los datos qué te permitirán conocer el estado de tu sitemap.
Canonicals

Revisa como se está utilizando la etiqueta rel=»canonical» en cada una de tus páginas.
Screaming es una herramienta ideal para auditar el uso del canonical en tu sitio y descubrir qué páginas sí contienen canonical, páginas sin canonical, canonicalizadas, etc.
Hreflang

Evalúa la implementación de las etiquetas hreflang en cualquier sitio web.
Screaming te mostrará qué páginas tienen hreflang, detalles sobre la etiqueta implementada y te mostrará los errores de forma agrupada.
Datos estructurados

Configura el rastreo de datos estructurados y analiza qué datos estructurados se detectan.
Podrás analizar el tipo de Schema detectado, errores de validación y otros datos qué te ayudarán a analizar el marcado de datos.
Usos avanzados de Screaming Frog
Conectar APIs
Screaming permite conectar diferentes APIs y extraer información adicional.
Actualmente, esta herramienta permite conectarse con las APIs de:
- Google Analytics.
- Google Search Console.
- PageSpeed Insight.
- Ahrefs.
- Majestic.
- Moz.
Análisis de contenido con Screaming Frog
En este caso, vamos a hacer uso de la herramienta para analizar qué páginas tienen un contenido pobre, duplicado o muy similar y su nivel de ortografía y gramática.
¡Empecemos!
¿Cómo configurar Screaming Frog para analizar el contenido?
Configurar correctamente hará que rastreemos el contenido adecuado, ni más ni menos, y que se analice de la forma correcta.
Contenido > Área del contenido
Screaming rastrea y muestra la información de recuento de palabras por página, contenidos semi duplicados y revisiones ortográficas y gramaticales.

Cuándo vayas a visualizar estos datos, para evitar que no aparezca información repetitiva que afectaría a la hora de interpretar los datos de forma válida.
Screaming por defecto excluye el menú de navegación y footer.
Sin embargo, si en tu web, estos elementos no son HTML5, no los podrá interpretar y excluir.
También es muy posible que te encuentres con otros elementos que te conviene excluir, como puede ser un sidebar.
En este apartado de configuración, puedes incluir o excluir elementos HTML, clases o ID para que solo se muestre el contenido que te interesa.
También puedes marcar la casilla de arriba, para que el texto ALT de las imágenes se incluya dentro del contenido de la página.
Contenido > Duplicados
La herramienta te informa del contenido duplicado exacto y del contenido semi duplicado.
Para este último tendrás que habilitarlo y configurarlo.
En el apartado anterior, excluimos y/o incluimos las partes de la página que te interesa que se tengan en cuenta dentro de este contenido semi duplicado.
Ahora pasamos a activar la casilla de «contenido semi duplicado«, al hacerlo, nos indicará el porcentaje a partir del cual te mostrará las direcciones que se encuentren como «contenido semi duplicado».
Screaming, por defecto, solo tiene en cuenta las páginas indexables, si quieres saber también la información de las urls no indexables, deberás desactivar la primera casilla.
Para conocer los datos, debes empezar el análisis de rastreo posterior.

Si posteriormente decides modificar este porcentaje o los elementos que anteriormente has decidido excluir/incluir, puedes volver a analizar el rastreo, sin necesidad de rastrear el sitio entero.
Contenido > Ortografía y gramática
Con esta herramienta tienes la posibilidad de revisar ortografía y gramática de páginas HTML.
En «Contenido > Área», ya excluiste los elementos HTML, clases y ID que no te interesa que aparezcan dentro de este contenido a revisar, ahora pasamos a configurar este apartado.

Primero, debes activar las dos pestañas de revisión y más abajo tienes dos opciones:
- En automático, screaming interpretará las etiquetas HTML de idioma de tu sitio y de no encontrar ninguna, empleará el idioma configurado.
- La opción manual hará que el rastreador directamente base el análisis en el idioma que se indica abajo.
En la siguiente pestaña puedes configurar las reglas gramaticales que se empleen.
En ignorar puedes incluir un listado de palabras o frases que ignorar a la hora de llevar a cabo la revisión de ese rastreo.
Y como última pestaña de configuración, en diccionario puedes incluir palabras o frases que ignorar en ese y en todos los rastreos.
Como puede ser tu nombre de marca o aquellos términos que ya sabes que no van a interpretarse correctamente y te interesa omitir.
Si posteriormente decides modificar esta configuración, sin necesidad de volver a rastrear el sitio entero, puedes actualizar la información de las urls aquí:
Analizando el contenido
Una vez has realizado la configuración, vamos a ver qué datos sacamos de esta herramienta para mejorar el contenido de tu web:
Contenido duplicado
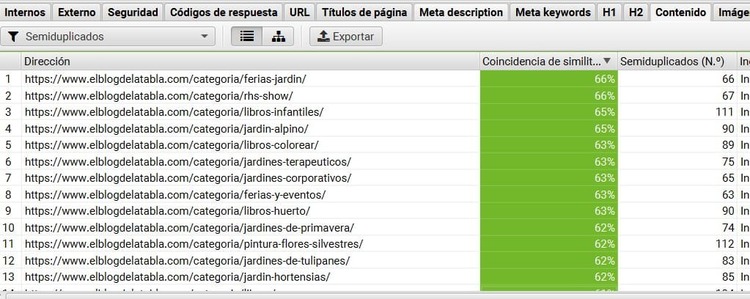
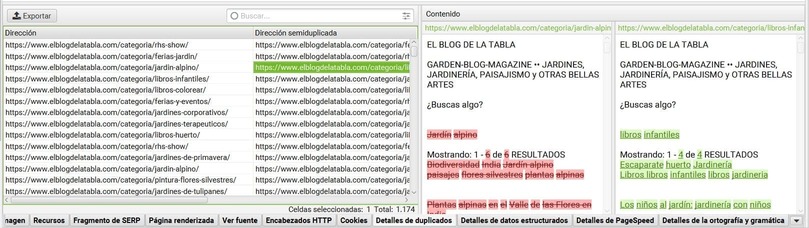
Primero, podrás ver las páginas con contenido exacto en la pestaña duplicados exactos.Y en semi duplicados, te mostrará de cada url, el porcentaje de similitud con otras páginas y el nº de páginas en las que se encuentra semi duplicado el contenido.

En el menú inferior, la pestaña «detalles de duplicados» te mostrará de forma visual que textos de la página se encuentran duplicados.
Páginas con poco contenido
Desde la pestaña de contenido, puedes ver el recuento de palabras de cada página y en el apartado páginas con poco contenido.
Podrás ver todas las páginas que se consideran urls con poco contenido.
Por defecto, screaming considera poco contenido, aquellas páginas que cuentan con menos de 200 palabras.
Puedes modificar este nº de palabras en: configuración → spider → preferencias.
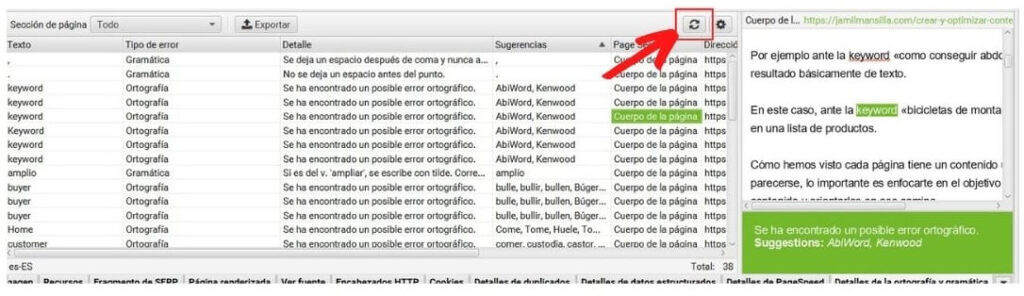
Ortografía y gramática
En las columnas del panel central podrás ver la cantidad total de errores que se encuentran en cada dirección.
Esto lo puedes relacionar con el recuento de palabras y tener una idea de las urls que deberías revisar primero.
La información más interesante de esta herramienta, la encontrarás en la pestaña detalles de la ortografía y gramática.
Donde te indicará información detallada de ese error y te aportará sugerencias.

Rastreos personalizados
Con las opciones de realizar rastreos personalizados podrás buscar y extraer casi cualquier dato que se encuentre dentro del código del sitio.

Búsqueda personalizada
Con esta función screaming te permite encontrar lo que quieras de tu sitio web.
La función personalizada buscará los elementos solicitados en el código HTML de cada página rastreada.
Dependerá de la configuración del modo de renderizado que busque en el código HTML estático o renderizado.
¿Cómo realizar una búsqueda personalizada?
Comentaremos las pestañas a rellenar de izquierda a derecha:
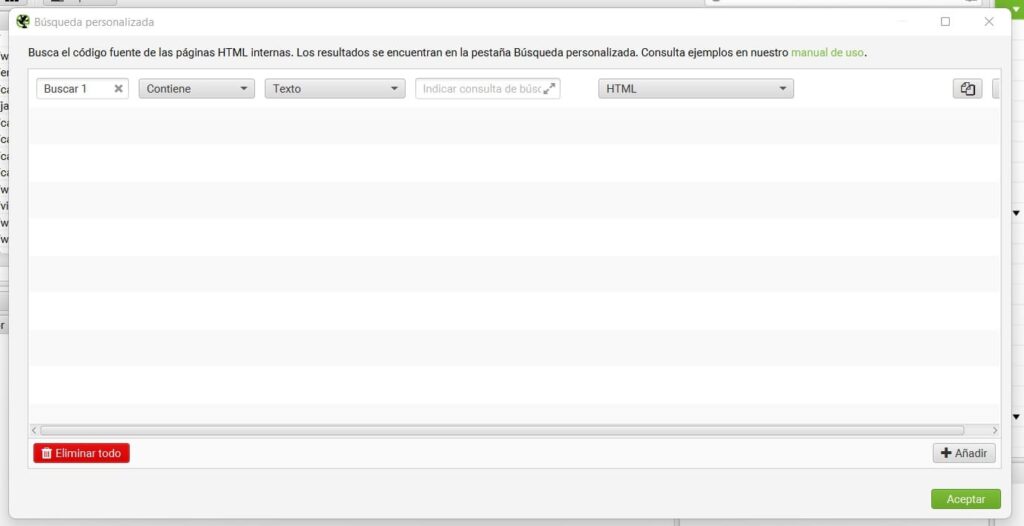
En el apartado de la izquierda, introduces el nombre con el que vas a identificar esa búsqueda.
En la siguiente pestaña, elige si te interesa ver las páginas que contienen ese elemento o las que no lo contienen.
Selecciona realizar la búsqueda utilizando texto o una expresión regular (screaming trabaja con la biblioteca de expresiones regulares de java).
Distinguir entre mayúsculas y minúsculas, al introducir texto: despliega la casilla y si quieres que busque la palabra o frase prestando atención a las mayúsculas seleccione la casilla, de lo contrario mostrará tanto mayúsculas como minúsculas.

Esto es muy útil para buscar por ejemplo el nombre de tu marca o producto y comprobar que está bien escrito en todas las páginas.
En caso de utilizar expresiones regulares se indicaría con la regla: (?i) antes de la palabra.
Otras expresiones regulares útiles son:
- \bpalabra\b: para buscar palabras exactas
- Separar con contra barra (|), de esta forma sumará varias palabras. Por ejemplo: \bpalabra1\b|\palabra2\b mostrará la cantidad de veces que aparecen “palabra1” y “palabra2” en cada página de forma exacta.
Cuándo hagas uso de esta herramienta, tendrás en cabeza las expresiones que más uses y otras deberás revisarlas en la guía o consultar en Google en el momento de necesitarlas.
Y en la última casilla, elige donde se debe realizar la búsqueda.
Tienes varias opciones, entre ellas, se encuentra área de contenido, esta es una sección que anteriormente en el apartado de configuración explicamos como configurarla para buscar solo el contenido que te interese.
Después, rastrea el sitio y podrás ver esta información en la barra superior o en el menú derecho.

Para el ejemplo de la imagen he buscado las páginas que contienen la palabra «planta» y me está mostrando la cantidad de veces que se repite esa palabra en cada url.
Puedes combinar varias búsquedas, como por ejemplo las páginas que contienen una keyword y no contienen otra keyword y comparar la búsqueda en el panel.
Como hemos visto, la búsqueda personalizada puede ser muy útil en algunos casos, pero como el nombre indica, solo busca, no extrae los datos, para esto pasamos al siguiente apartado.
Extracción personalizada
Esta función permite extraer cualquier dato que se encuentre en el código HTML de las urls que devuelven un código 200, a través de CSSParth, XPath y regex.
Dependerá de la configuración del modo de renderizado, que la búsqueda se ejecute sobre el código HTML estático o renderizado si seleccionas que represente el código JavaScript.
Algunos ejemplos de la función de extracción pueden ser:
- Ver los encabezados h3 de tus páginas.
- Mostrar el número de comentarios de cada post.
- Extraer todo el texto de las páginas.
- Etc.
¿Cómo usar la extracción personalizada de Screaming?
Para configurar la búsqueda. Accede a configuración > Personalizado > Extracción y llegarás a un panel como el siguiente:

- En la primera casilla de la izquierda, simplemente introduce cómo quieres que se nombre a tu solicitud de extracción.
- En el siguiente apartado selecciona a través de que se extraerá la información: XPath, Ruta CSS o expresión regular.
Dependiendo del elemento que quieras extraer te será más conveniente una opción u otra.
Puedes ver ejemplos de usos de XPath y regex.
XPath y Ruta CSS, permitirán seleccionar qué información extraer con los filtros:
- Extraer HTML interno. Extrae el contenido HTML interno del elemento seleccionado y de sus sub elementos.
- Extraer elemento HTML. Extrae el elemento seleccionado y su contenido interno.
- Extraer texto. Extrae el texto del elemento seleccionado y de sus sub elementos.
- Valor de función. Devolverá el resultado de la función que indiquemos. Por ejemplo, conocer la cantidad de etiquetas h2 de cada página con la función contar (//h2).
Una vez configurado esto, y habiendo introducido el elemento o expresión regular, puedes aplicar esta búsqueda, rastreando un sitio o utilizando el modo lista.
Para entenderlo mejor, pasemos a ver un ejemplo:
Ejemplo: Conocer el porcentaje de descuento que aplica un competidor a cada producto.
Imagina que esta es una web de tu competencia, y te interesa conocer qué porcentaje de descuento está aplicando en cada producto.

¿Cómo puedes averiguar esto?
La herramienta ofrece una función de búsqueda de la página en internet donde te facilita buscar y seleccionar el código.

Aunque, en este caso, lo haré de la forma tradicional.
Situándonos en la página, para buscar en el código, presionamos botón derecho → inspeccionar y con ayuda del selector → marcamos ese elemento y copiamos con XPath.

Después de esto, acudimos a Screaming y copiamos en el apartado de extracción la información que nos ha copiado el selector.

Ahora que ya lo tenemos configurado, rastreamos la página del competidor, acudimos a la pestaña de extracción y veremos los siguientes datos, que serán el resultado deseado.

Consejos para sacar el máximo partido a Screaming Frog
La mejor recomendación que te daré es que antes de realizar un rastreo, te realices la pregunta:
“¿Qué objetivos tengo y qué configuración necesito?”
Respondiendo esta pregunta, ahorras tiempo, y segmentarás mejor la información.
Dicho esto, te dejo algunos tips interesantes:
- Cuando encuentres datos que llevan la «i». Significa que debes analizar el rastreo para visualizarlo.
- Para tener una visión más clara de la información. Limpia la barra superior, elimina y ordena las columnas según tus preferencias y guarda esta configuración.
Además, al hacer clic derecho sobre una pestaña, Screaming te permite configurar las pestañas de cualquier sección.

Desmarca las casillas que no te interesen y para ordenar simplemente arrastra las columnas hacia donde te interese.
- Screaming + Excel. Screaming es excelente, pero si además sabes combinarlo bien con Excel, podrás exprimir los datos al máximo.
Además, si eres más fan de Google Sheets como yo, la herramienta te permite conectar con tu cuenta y exportar datos de forma muy práctica.
- Haz uso de Informes y exportación en bloque. Desde aquí, podrás exportar datos rápidamente.
Por ejemplo en «Resumen SERPs», reportar un informe de los metadatos de tus páginas.
- Screaming permite separar las ventanas, presionando clic derecho → Desasociar, para tratar la información de forma más práctica.
- Si por algún caso, has modificado las columnas y/o pestañas y deseas restablecer la configuración inicial. Puede hacerlo desde configuración > Interfaz de usuario.
- Es interesante que sepas que screaming te permite programar un crawleo.
Conclusión
Como habrás visto, Screaming Frog es increíblemente poderoso, realmente aplicando un uso completo de este, puedes tener el SEO de un sitio bien optimizado sin tener que acudir a otras herramientas.
Ahora, te animo a probar lo que te he explicado en esta guía, así te irás familiarizando y estarás más cerca de dominar screaming frog.
¿Tienes alguna duda? ➯ ¡Déjame un comentario!